
Quasar: Pt. 3 — Technical Direction
Quasar Post-Mortem: Part 3
Below is a summary of the articles in this post-mortem. Although having full context is recommended, the subject matter explored herein covers many disciplines and can be consumed non-linearly. Feel free to jump around to whichever area interests you most:
Uncanny Valley
Art Direction
Developing for DEI
Regional Template System
Designing for Impatience
Design Artifacts
Avatar Samples
Personal Contributions
Technical Direction:
What is Quasar, technically?
Quasar is the name of a procedural avatar system developed [initially] for iOS devices which support the ARKit face tracking API — however, Quasar was conceived, designed and built from the very beginning in an interoperable manner which could be accessed on any platform; from AR devices such as iPhone [with TrueDepth] and Magic Leap, to VR devices such as the HTC Vive, and even a web-based variant which leverages WebGL paired with a typical webcam and face tracking library such as OpenCV.
Quasar was designed as a series of microservices which would be favorable in terms of interoperability:
Houdini Service
Headless instance of Houdini running on an Ubuntu AWS server
Houdini receives one of the following:
ARKit fitted mesh data (TrueDepth)
FBA point patterns (Webcam)
Anthropometric values from Anthropometric Database (User input)
Houdini generates custom fitted procedurally generated 3D models
Substance Service
Substance Engine running on an Ubuntu AWS server
Substance Engine receives RGB UV-space texture data
Substance Engine stylizes the textures and generates additional PBR surface maps necessary to render the avatar in-conversation
Substance Engine exports these PBR textures for further editing in the Shell Interface
Shell Interface (Unity, initially)
HTML/CSS/WebGL interface which allows the user to make changes to their avatar
Shell receives both the 3D models from the Houdini Service as well as the 2D PBR texture maps from the Substance Service
Shell allows the user to make adjustments to the 3D models (e.g. selecting a different regional template) and/or the PBR textures (e.g. selecting a different skin tone, etc)
Shell sends the choices (simple int values) for those augmented 2D textures and 3D models to Houdini, which regenerates the affected assets and sends it to the FBX-to-glTF 2.0 converter — resulting in a binary glTF (GLB) asset ready for use in-conversation
Shell also allows the user to input anthropometric measurements of their face when no capture equipment is available
FBX-to-GLTF 2.0 Converter
Small component for packaging the materials, textures and models as a binary glTF file
FBA Interpreter
Responsible for converting either voice input (phoneme detection) or face tracking data to an [interoperable] FBA data stream
Transmits facial performance via WebRTC metadata channel
Note: This isn’t a component built-in to Quasar, but it is important to know this is how interoperability was approached
The output of Quasar is a standards-based (binary glTF) avatar file which includes the following features:
3D models which are uniquely shaped and fitted to the user’s physical face surface, generated via ‘transplanting’ a frame of depth data from the iOS TrueDepth camera while the user provides a neutral face pose
glTF (GLB) nodes include:
Head (includes 51 FACS face muscle blendshapes)
Eyebrows
Hair
Teeth
Tongue
Eyes
Glasses
2D PBR skin material which is unique to the user’s physical appearance, generated via captured RGB data from the iOS front-facing camera
gltf (PBR) textures include:
Albedo
Metalness
Roughness
Occlusion
Emission
Note: Proper SSS would have been preferred, but the base glTF 2.0 spec does not support SSS
Developing for Interoperability:
What types of human data are we collecting at avatar setup?
This diagram describes the data collection process of creating a procedural avatar depending upon which platform is being used at time of initial setup, and where that data ends up (from a very high level).
Technically, the goal of Quasar was always to get as much physical data on the user as possible, regardless of platform, and then leverage it to the fullest extent possible to recreate an individual’s likeness.
As we can see in the above diagram, the ideal platform for human data collection is the iPhone X (or later) which provides the most and best sources (depth data reigns supreme, see Bias in CV section) of rich human data via the ARKit API. The webcam input provides the same amount of sources, but the accuracy of that tracking data is nowhere near the resolution of the ARKit API.
After the data has been collected and used to generate an avatar, how does that avatar get ‘driven’ at runtime?
Basically, this describes which sources of data get translated by the FBA Interpreter — effectively all of them. Even voice gets translated to FBA — then decoded as blendshape values to produce the appropriate viseme. This diagram could have probably been a bulleted list, but I sure do appreciate visuals:
Note: The FBA Interpreter is covered in detail further below.
And finally — what would happen if you took an avatar generated from one platform, and logged into a different platform to use the same avatar?
This table describes how, or which, features carry over from one platform to another:
Table Explanation:
The left column is describing the inherently available features of a user’s avatar based on the client platform used at time of avatar setup. All underlined items are based on visual human data — face tracking, eye tracking, or image/video.
Note: All of these setup clients could potentially use user-input anthropometric values to gain a semi-unique face shape, and as a result, semi-unique face movement. I omitted this information as the table is meant to describe the differences rather than similarities.
The 4 columns on the right are describing what the user’s avatar will look like to the conversation peers based on the client from which they originally set up their avatar, and from which platform they are currently communicating in the conversation. The main takeaway here is that when a user supplies real-world data from any source, that data will be leveraged and represented (to other clients) whenever possible, based on the available input at runtime.
Also to note, for this table we are assuming the user has set up their avatar on a particular client and they have not supplied any additional human data to generate a new avatar after switching to a different client.
Example 1: If a user sets up a new avatar on iOS and then uses it on a PC Vive client (which has no face tracking available — voice input only) their avatar’s facial articulation will be limited to those FACS channels which relate to speech-detected phonemes.
Example 2: If a user sets up a new avatar on PC Vive and then uses it on iOS, they will have the full facial articulation provided by the ARKit API, but they will have generic facial features as the PC Vive platform does not have the input hardware to capture a user’s facial features.
Interoperability Standards:
What is glTF?
glTF is an acronym for Graphics Language Transmission Format.
According to The Khronos Group:
glTF™ (GL Transmission Format) is a royalty-free specification for the efficient transmission and loading of 3D scenes and models by engines and applications. glTF minimizes the size of 3D assets, and the runtime processing needed to unpack and use them. glTF defines an extensible, publishing format that streamlines authoring workflows and interactive services by enabling the interoperable use of 3D content across the industry
Essentially, glTF is an up and coming interoperable standard for 3D scene data which is quickly finding adoption across industry spectrums. In fact if you are on Windows 10, right now, you can already open a glTF file with the preinstalled Windows 3D Viewer app!
I don’t want to waste much time covering glTF as there are many more, and much better, destinations to learn about glTF:
Note: I’ll provide avatar GLB samples in the conclusion section — which you can then drag and drop in an online viewer like Don McCurdy's online viewer and play with the face articulation yourself!
What is FBA?
FBA is an MPEG4 video codec developed for the purpose of tracking and encoding Face and Body Animations.
The FBA Codec offers:
86 Face Animation Parameters (FAPs) including visemes, expressions and low-level parameters to move all parts of the face
A pattern of facial feature points for any application that needs well-defined facial landmarks
196 Body Animation Parameters (BAPs) consisting of joint rotation angles
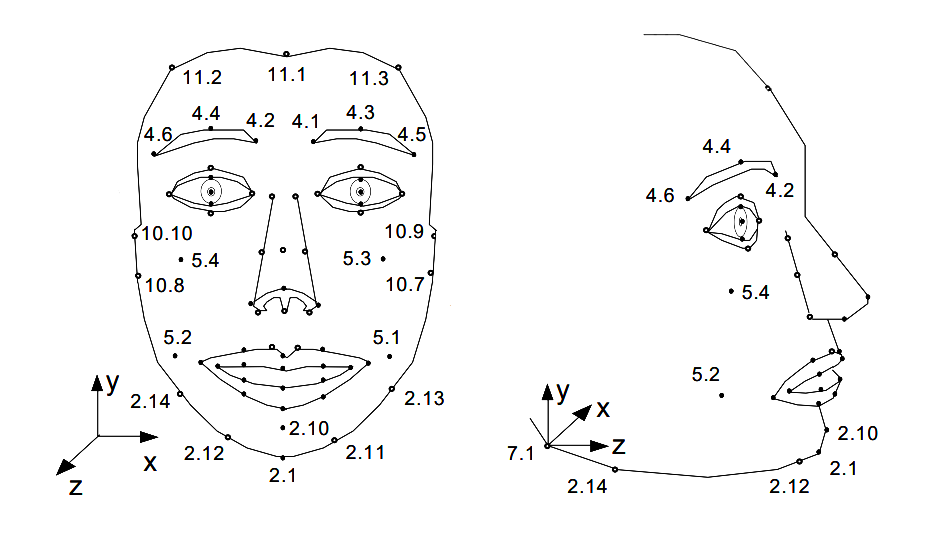
Image courtesy of Visage Technologies
Why use the FBA codec?
FBA is useful in the same way packaging the user’s exported avatar as a standard binary glTF file (*.GLB) is useful — FBA is a platform agnostic standard. While glTF is used as an interoperable ‘container’ for the avatar itself, FBA is the interoperable data stream for transmitting the animation data needed to articulate, or ‘drive’, the glTF asset at runtime.
Each platform targeted by Quasar had its own proprietary APIs for tracking human animation states:
iOS (iPhone X+) uses the ARKit API which provides:
Head location/rotations
Full body location/rotations
52 Face blendshape coefficients — these 52 blendshapes map very closely to each of the individual facial muscle movements possible with a fully articulable human face (i.e. ARKit provides us a FACS — Facial Action Coding System)
Magic Leap uses the Lumin SDK Headpose which provides:
Eye rotations
Head location/rotations
Hands location/rotations
PC (HTC Vive) uses the SteamVR/Steamworks API
Eye location (IPD only)
Head location/rotations
Hands location/rotations
PC (Web) uses the OpenCV API
Facial feature point pattern tracking
Full body location/rotations
As we can see, each of these platforms provides varying levels and types of human animation data; each platform also employs its own method to track and transmit this animation data. If we could somehow use FBA facial point patterns as the basis for Quasar’s input (both initial capture data at avatar setup and/or runtime articulation), then we could theoretically support virtually any device with a camera!
What is the FBA Interpreter?
The “FBA Interpreter'' is responsible for converting either voice input (phoneme detection) or face tracking data to an [interoperable] FBA data stream. That data stream can then be decoded and translated into the client platform’s preferred format (e.g. ARKit blendshape values, etc) to drive the avatar’s facial articulation in real-time.
How does it work?
In order to animate ARKit’s face mesh with FBA data there must exist a library of facial movement definitions which correspond to similar facial movement definitions of FBA — essentially a dictionary lookup.
In the case of iOS, that library is an array of 51 blendshape channels provided by the ARKit API, and the values (coefficients) of those channels are constantly changing and shifting their influence on vertex locations while face tracking is active — however, the vertex order is a constant. This means a reliable connection can be made between the movement of a select group of vertices and the equivalent FBA Facial Action Parameter (FAP).
In the case of FBA, as mentioned, the equivalent library is an array of 86 Facial Action Parameters — as they are not 1:1 to ARKit, translations are necessary to combine multiple FAPU values to correspond to a single ARKit blendshape channel.
A Little More:
The FBA data is sent as Facial Action Point Unit (FAPU) values which inform the ratios and distance between specific Facial Action Parameters (FAPs). Each FAP is defined on which Facial Point (FP) it acts, in which direction it moves, and which FAPU is used as the unit for its movement.
For example, the Facial Action Parameter for “open_jaw”, moves the Feature Point 2.1 (see figure, bottom of the chin) downwards and is expressed in MNS (mouth-nose separation) units. The MNS unit is defined as the distance between the nose and the mouth. The Mouth Nose Separation Unit is the Facial Action Parameter Unit (FAPU) which would be transmitted to trigger the equivalent movement of the ARKit face mesh.
The other function of the Interpreter is to effectively convert voice data to FBA data — this is useful for both face-tracked and non-face-tracked platforms alike:
iOS users may lose face tracking for one reason or another (e.g. moving their face out of view) — in this scenario a speech detection script can be used as the basis for facial articulation:
For example, when the phoneme “oo” is detected from the microphone, the client sends a “phoneme preset” of the blendshapes and their values necessary to make that same face pose when speaking that particular phoneme (i.e. the viseme)
VR HMD users generally have no tracked face data — again, the mic input drives facial movements based on speech recognition
In both of these platform’s scenarios, without live face tracking, the default level of articulation is limited to animated phonemes — but any amount of (accurate) facial performance is better than none at all
FBA Shortcomings
This all sounds great in theory, but FBA is a 20+ year old standard which must estimate 3D data (from 2D data), rather than natively measuring 3D surface data with depth sensing cameras such ARkit or Intel’s RealSense cameras. This means facial performance data will naturally be lost in translation when transmitting face poses from devices with depth sensing support. Even the best demos of FBA exhibit jittery detection, and I am not faulting the technology itself — it is astounding FBA can infer as much 3D data as it does. It’s just not as good as the data from an IR/lidar camera.
If I were to go back in time, I would have spent time researching and campaigning for a different solution to transmit facial performance data in the highest quality possible based on platform capabilities.
Functional Design
I authored the following diagram as a high-level overview for explaining the expected functional configuration of Quasar’s systems — however, some of these systems didn’t reach full maturity:
The “3D Face Scan Database” needed many more unique users (especially people of color) to supply a capture of their face in order to reach a coverage threshold which would allow for a confident, unbiased, deployment of an automated statistically-based regional template generator (part of RTS, covered previously) which routinely takes the latest user face scans, sends them to the 3D Face Scan test/training set, and regenerates the templates with this new data
The “Houdini Hair Styling Tool” also did not achieve full maturity simply due to prioritization — achieving an accurate and appealing face was paramount to all other goals
Note: If you thought “The hair models really aren’t the same fidelity or style as the faces” — you are right! In fact, the hair models in the avatar renders were authored years prior for a legacy avatar system which employed an ultra-stylized “Mr Potato Head” system for mixing and matching preset facial features — unfortunately, the result is an inconsistent art style, texel density, and mesh resolution when contrasted with Quasar heads
Integrating Quasar into a larger application
And finally, here is a high level diagram I authored to communicate to the team how Quasar could be integrated to a communication application. (Note: Some component names have been obfuscated.)
Uncanny Valley
Art Direction
Developing for DEI
Regional Template System
Designing for Impatience
Design Artifacts
Avatar Samples
Personal Contributions